
Gæsteindlæg: Hvorfor frie kort?
Dette gæsteindlæg er skrevet af Leif Lyngby Lodahl, der er It-arkitekt i Ballerup Kommune, og som blandt andet har baggrund som talsmand for open-source kontorpakken Openoffice i Danmark. Du kender måske hjemmesiden www.openstreetmap.org. Gør du ikke, vil jeg foreslå, at du prøver. Hjemmesiden er, hvad vi kan kalde Wikipedia for landkort. Lige som Wikipedia er garant […]
Read more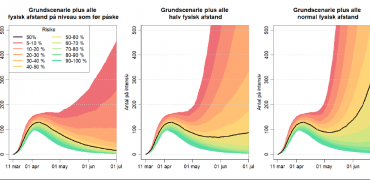
Behov for åbenhed omkring data og modeller bag corona-beslutninger
Under corona-krisen har fremskrivninger baseret på data og modeller haft afgørende betydning som grundlag for vigtige politiske beslutninger. Beslutningerne er politiske, men modellerne er tilstræbt objektive. Hvorfor er det vigtigt, at vi kender til disse modeller? Vi har spurgt Mikkel Freltoft Krogsholm. Mikkel er data scientist og har i de seneste måneder selv arbejdet indgående […]
Read more
Nordisk-baltisk samarbejde om open data relateret til anti-korruption
Open Knowledge Danmark var med da nordiske og baltiske repræsentanter fra Open Knowledge og Transparency International mødtes til en workshop med temaet “Building a Nordic Anti-Corruption Data Ecosystem” i Riga, oktober 2019. Der blev arbejdet på udfordringer omkring anti-korruptions data: Hvad er situationen i de forskellige lande? Hvilke barrierer for åbenhed om politiske data møder […]
Read moreRigsrevisionen om statens brug af åbne data
Rigsrevisionen har undersøgt statens brug af åbne data og Open Knowledge Danmark har bidraget med input undervejs. I deres rapport anbefaler de at gøre klar til indførelsen af ”open by default” for data fra staten i Danmark. Princippet indebærer, at alle ministerier bør åbne deres data. Rigsrevisionen har også lavet en interaktiv visualisering af statens […]
Read moreNGOs urge European Parliament to vote for free access to company and UBO registers
Denne blogpost blev oprindeligt publiceret af Open State Foundation. Open Knowledge Danmark er medunderskriver af henvendelsen til medlemmerne af Europa-Parlamentet. On Monday the 3rd of December the European Parliament talks about the revision of the Public Sector Information (PSI) Directive. This Directive promotes the release of re-usable information from European public sector organizations. The revision focuses […]
Read more
Merete Sanderhoff vinder Åben Data Prisen 2018
Short summary in English: One day early we celebrated Open Data Day 2018 in Copenhagen with Ethos Lab and Open4Citizens. The winner of the first Danish Open Data Award was announced: Merete Sanderhoff from SMK for her work on Wiki Labs and OpenGLAM. Furthermore we had three inspiring presentations on Open4Citizens by Nicola Morelli, on Electricity Map by Olivier Corradi and on Wikidata by Finn Årup […]
Read more
Åben data prisen 2018
Open Knowledge Danmark har indstiftet en ny pris: Åben Data Prisen. Prisen er indstiftet i 2018 i samarbejde med ITU’s Ethos Lab og Open4Citizens-projektet under AAU, alle tre organisationer er repræsenteret i pris-komiteen. Prisen har til formål at hædre personer, grupper eller projekter, der udmærker sig særligt i forhold til anvendelse og udbredelse af åben data. Kriterier […]
Read more
Join us for open data day 2018 in Copenhagen
Open Data Day is coming up. This year we have partnered with Open4Citizens and Ethos Lab to host an event Friday 2 March in Copenhagen (see details below). At the event we will celebrate open data with informal socializing and short inspiring talks on open data. At the event we will announce the winner of the Danish Open […]
Read more
Regeringen har besluttet at åbne DMI’s data
Open Knowledge Danmark bifalder, at Danmark nu også åbner for gratis videreanvendelse af klimadata og meteorologiske data. Flere andre lande heriblandt Norge, Sverige, Finland, England, Holland og Tyskland har allerede åbnet deres meteorologiske data med stor stigning i efterspørgsel og videreanvendelse til følge. Den åbne adgang til klimadata kan blandt andet hjælpe til at forebygge […]
Read more
Gæsteindlæg: Åbne offentlige data – en ny form for offentlig service
Dette er et gæsteindlæg af Kristian Holmgaard Bernth, der er chefrådgiver i firmaet Seismonaut. Indlægget er oprindeligt skrevet som artikel på Seismonauts hjemmeside i en lidt længere version, der kan findes her. Seismonaut har blandt andet arbejdet med hvordan offentlige åbne data i større grad kan finde anvendelse i virksomheder og rådgivet myndigheder omkring deres udstilling af åbne data. […]
Read more